1. 데이터베이스 개념
# 관계형 데이터모델
- 2차원 테이블 형태의 데이터베이스를 칭하며
- 각 열(column)을 '속성', '컬럼', '필드' 라 부름
- 각 행(row)를 '튜플(tuple)', '속성값 집합', '레코드'라 부름
- 도메인(domain) : 하나의 속성이 취할 수 있는 모든 값의 범위
- 종류 : Oracle, MySQL, MSSQL, IBMDB2, SQLite, MariaDB, Postgre 등
# SQL ( Structured Query Language)
- 1974년 IBM연구소에서 System R로 시제품_ 집단,그룹화,갱신연산 등
- 1986년 ASNI(미국표준기구)에서 SQL표준을 채택
- 여러 상용 DBMS가 존재하며 각각 지원하는 SQL 기능에는 약간 차이가있음
- 자연어에 가까운 구문 사용하는 것이 장점
- 분류 : 권한 및 역할에 따라 DQL , DML, DDL, DCL 로 나누어 부름
- DQL( Data Query Language) : 사용자가 데이터 조회하는 언어 ex. SELECT
- DML( Data Manipulation Language) : 데이터를 직접 조작가능 ex. SELECT, INSERT, UPDATE, DELETE
- DDL ( Data Definition Language) : 데이터베이스 구축,수정_ 데이터형식,접근방식정의
ex. CREATE,ALTER,DROP,RENAME,TRUNCATE
- DCL( Data Control Language) : 데이터접근,사용권한 관리 ex. GRANT, REVOKE
2. SQL 언어
2-1. 데이터검색
[ 기본개념]
- 데이터베이스 내 테이블에 저장된 데이터검색
- 결과는 테이블형태로 출력
- 질의어(SQL) 끝은 세미콜론( ; )으로 구분
- 특수기호 : ' * ' 전체를 의미,
[ 예약어 ]
- DESC {테이블명} : 테이블 컬럼의 데이터타입 조회
- SELECT : 출력시킬 테이블의 컬럼지정 (+ DISTINCT : 중복제거 조회) ( + AS : 컬럼별칭지정)
- FROM : 조회할 테이블 지정
- WHERE : 조회할 데이터의 조건식 지정
- GROUP BY : 조회할 데이터의 묶음 지정
- HAVING : 그룹화하여 조회된 데이터의 조건 지정
- ORDER BY : 조회할 데이터의 정렬기준 지정 ASC오름차순, DESC내림차순
[ 연산자 ]
- 산술연산자 : +, -, *, /
- 비교연산자 : =, >, <, >=, <=, <>(NOT)
- 논리연산자 : AND, OR, NOT
- 범위연산자 : BETWEEN {val_1} AND {val_2}
- IN 연산자 : 여러가지 값에 대한 OR연산자 대신 사용 ex. IN ( 10, 30 )
- NOT IN 연산자 : IN의 반대, 아닌값 조건 ex. NOT IN (10, 30)
- LIKE 연산자 : 값의 일부 정규식으로 지정 ex. {column} LIKE 'A%'
[ 서브쿼리 ]
- SQL문 안에 다른 SQL문을 중첩하여 사용
- 괄호로 묶어서 구분
- 서브쿼리 내 ORDER BY는 의미가 없음
- 단일행서브쿼리 : 서브쿼리 결과로 1개의 컬럼만 나올 시, 조건식의 '=' 등호와 연계
- 다중행서브쿼리 : 서브쿼리 결과로 여러 컬럼이 나올 시 조건식의 'IN' 연산자 등과 연계
- EXISTS : 서브쿼리와만 사용가능, 서브쿼리의 결과가 존재할 경우만 메인쿼리 수행
ex. SELECT * FROM {table} WHERE EXISTS (SELECT~~)
[ 기타 ]
- UNION : 여러개 SQL구문 결과를 묶어줌_컬럼수동일할 경우만
- NULL : 없는값으로 '0'과는 다름
- IS NULL & IS NOT NULL : NULL 없는값인지 확인, 등호로 확인 시 (=NULL) 'NULL' 문자열을 의미
[ 단일행 함수 - 문자열 ]

- INITCAP, LOWER, UPPER
SELECT ename, INITCAP(ename), LOWER(ename),UPPER(ename)
FROM scott.emp;
- LENGTH, LENGTHB
SELECT LENGTH('홍길동'), LENGTHB('홍길동')
FROM scott.emp;
- CONCAT
SELECT ename,job,CONCAT(ename,job)
FROM scott.emp;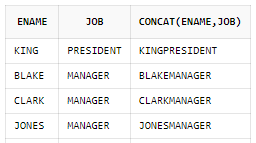
- SUBSTR
SELECT ename, SUBSTR(ename,2,3)
FROM scott.emp;
- REPLACE
SELECT ename, REPLACE(ename,SUBSTR(ename,2,2),'**')
FROM scott.emp;
[ 단일행함수 - 숫자 ] - ROUND, TRUNC, MOD

SELECT ROUND(123.456,2), TRUNC(123.456), MOD(123,10), CEIL(123.456),FLOOR(123.456),POWER(3,4)
FROM dual;
[ 단일행함수 - 날짜 ] - SYSDATE, MONTHS_BETWEEN
- SYSDATE : 시스템 현재 날짜와 시간
- MONTHS_BETWEEN : 두 날짜 사이 개월 수 ( 앞이 더 최신일 경우 양수)
- ADD_MONTHS : 주어진 날짜에 개월을 더함
- NEXT_DAY : 주어진 날짜를 기준으로돌아오는 날짜 출력
- LAST_DAY : 주어진 날짜가 속한 달의 마지막 날짜 출력
SELECT SYSDATE,TO_DATE('210101','YYMMDD'), MONTHS_BETWEEN(SYSDATE,TO_DATE('210101','YYMMDD'))
FROM dual;
[ 단일행함수 - 변환 ] - TO_CHAR, TO_DATE, NVL, DECODE
- TO_CHAR : 숫자 또는 날짜 데이터를 문자형으로 변환
( 포맷 : $-달려표기 | 0-자리수유지 | 9-숫자자리 | ' , ' : 천단위 | ' . ' : 소수점 )
- TO_NUMBER : 숫자형태를 띈 문자형 데이터를 실제 숫자로 변환
- TO_DATE : 문자형 데이터를 실제 날짜 데이터로 변환
- NVL(대상열, 치환값) : NULL값을 만나면 값 치환
- DECODE(대상열, 조건값, 참일때 값, 거짓일때 값) : 등호조건 참,거짓 값 치환
- Ex. TO_CHAR
SELECT TO_CHAR(12345.678,'$0999,999.999')
FROM dual;
- Ex. NVL
SELECT ename, comm, NVL(comm,999)
FROM scott.emp;
- Ex. DECODE
SELECT ename, deptno, DECODE(deptno, 30, 'Check','-')
FROM scott.emp;
[ 집계함수 ] - COUNT, SUM, AVG, MAX, MIN
SELECT COUNT(*), COUNT(ename), SUM(sal), AVG(sal), MAX(sal),MIN(sal)
FROM scott.emp
WHERE deptno = 10;
[ 그룹화 ] - GROUP BY, HAVING
SELECT deptno, SUM(sal), AVG(sal)
FROM scott.emp
GROUP BY deptno;
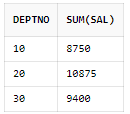
SELECT deptno, SUM(sal)
FROM scott.emp
GROUP BY deptno
HAVING COUNT(*) > 2
ORDER BY deptno;